World first: brain implant lets man speak with expression and sing] (Analysis of a 45-year-old man with severe speech disability
A man with a severe speech disability has a brain implant that is able to translate his neural activity into words. The device conveys changes of tone when he asks questions, emphasizes the words of his choice and allows him to hum a string of notes in three pitches.
“This is the holy grail in speech BCIs,” says Christian Herff, a computational neuroscientist at Maastricht University, the Netherlands, who was not involved in the study. This is a continuous speech.
The study participant, a 45-year-old man, lost his ability to speak clearly after developing amyotrophic lateral sclerosis, a form of motor neuron disease, which damages the nerves that control muscle movements, including those needed for speech. Although he could still make sounds and mouth words, his speech was slow and unclear.
Source: World first: brain implant lets man speak with expression ― and sing
Assessing the Inteligibility of Voice Synthesis from Neurological Activity and Biosignal Signals: From Audio Spectra to Spectrograms of Multiple Neural Electrodes
“We don’t always use words to communicate what we want. We have people that do not agree with us. We have other expressive vocalizations that are not in the vocabulary,” explains Wairagkar. We decided to adopt this approach in order to do that.
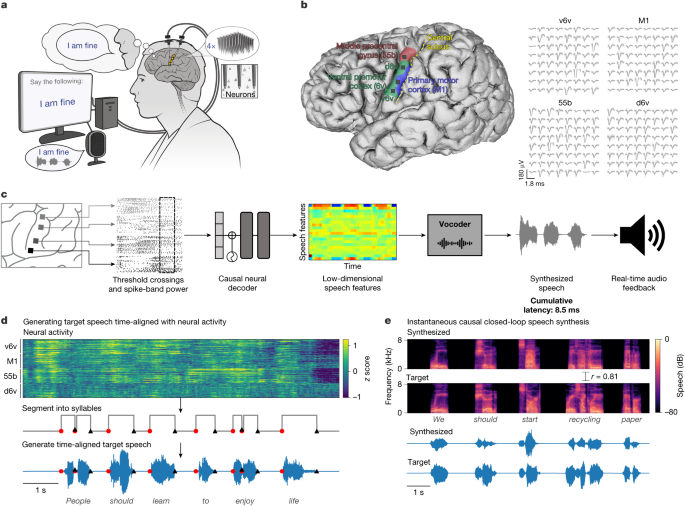
The team also personalized the synthetic voice to sound like the man’s own, by training AI algorithms on recordings of interviews he had done before the onset of his disease.
a. Three example trials’ audio recording, audio spectrogram, and the spectrograms of the two most acoustic-correlated neural electrodes. Examples are shown for the three types of speech tasks. The prominent spectral structures in the audio spectrogram cannot be observed even in the top two most correlated neural electrodes. An increase in neural activity has been observed before the start of a speech, reflecting speech preparation and further arguments against acoustic contamination. Note that in the word emphasis example, the last word ‘going’ is not vocalized fully (there is minimal activity in its audio spectrum), yet an increase in neural activity can be observed that is similar to other words. The bottom row shows the Contamination matrices and statistical criteria, which show if the trial is significantly acoustically contaminated or not. A. An example trial of attempted speech with simultaneous recording of neural signals and various bio signals is included. Separate independent decoders were trained to synthesize speech using each of the biosignals (or all three together). c. Intelligible speech could not be synthesized from biosignals measuring sound, movement, and vibrations during attempted speech. The Pearson correlation coefficients are cross-validated. (compared to target speech) of speech synthesized using neural signals, each of the biosignals, and all biosignals together. Reconstruction accuracy is significantly lower for decoding speech from biosignals as compared to neural activity (two-sided Wilcoxon rank-sum, P = 10−59, n = 240 sentences). Pearson correlation coefficients of speech decoding from biosignals and neural signals are usually non-overlapping in their distribution, indicating that synthesis quality is much lower than that of neural signals. To assess the intelligibility of voice synthesis from neurological activity and biosignals, naive humans performed an open transcription of 30 synthesized trials using both the mics. Neural decoding of stethoscope recordings had a word error rate of 100%, but median phoneme and word error rates were significantly lower. This means that speech cannot be read from biosignals.